Unless you live under the proverbial rock, you surely have come across Internet memes a few times. Memes are basically viral images, videos, slogans, etc., which might morph and evolve but eventually enter popular culture. When thinking about memes, most people associate them with ironic or irreverent images, from Bad Luck Brian to classics like Grumpy Cats.
Bad Luck Brian (left) and Grumpy Cat (right) memes.
Unfortunately, not all memes are funny. Some might even look as innocuous as a frog but are in fact well-known symbols of hate. Ever since the 2016 US Presidential Election, memes have been increasingly associated with politics.
Pepe The Frog meme used in a Brexit-related context (left), Trump as Perseus beheading Hillary as Medusa (center), meme posted by Trump Jr. on Instagram (right).
But how exactly do memes originate, spread, and gain influence on mainstream media? To answer this question, our recent paper (“On the Origins of Memes by Means of Fringe Web Communities”) presents the largest scientific study of memes to date, using a dataset of 160 million images from various social networks. We show how “fringe” Web communities like 4chan’s “politically incorrect board” (/pol/) and certain “subreddits” like The_Donald are successful in generating and pushing a wide variety of racist, hateful, and politically charged memes.
It’s normally in the final seconds of a TV or radio interview that security experts get asked for advice for the general public – something simple, unambiguous, and universally applicable. It’s a fair question, and what the public want. But simple answers are usually wrong, and can do more harm than good.
For example, take the UK government’s Cyber Aware scheme to educate the public in cybersecurity. It recommends individuals choose long and complex passwords made out of three words. The problem with this advice is that the resulting passwords are hard to remember, especially as people have many passwords and use some infrequently. Consequently, they will be tempted to use the same password on multiple websites.
Password re-use is far more of a security problem than insufficiently complex passwords, so advice that doesn’t help people manage multiple passwords does more harm than good. Instead, I would recommend remembering your most important passwords (like banking and email), and store the rest in a password manager. This approach isn’t perfect or suitable for everyone, but for most people, it will improve their security.
Advice unfit for the real world
Cyber Aware also tells people not to write down their passwords, or let anyone else know them – banks require the same thing. But we know that people commonly share their banking credentials with family, for legitimate reasons. People also realise that writing down passwords is a pretty good approach if you’re only worried about internet hackers, rather than people who can get close to you to see the written notes. Security advice that doesn’t stand up to scrutiny or doesn’t fit with people’s lives will be ignored – and will discredit the organisation offering it.
Because everyone’s situation is different, good security advice should include helping people to understand what risks they should be worried about, and to take steps that mitigate these risks. This advice doesn’t have to be complicated. Teen Vogue published a tutorial on how to select and configure a secure messaging tool, which very sensibly explains that if you are more worried about invasions of privacy from people who can get their hands on your phone, you should make different choices than if you are just concerned about, for example, companies spying on you.
The Teen Vogue article was widely praised by security experts, in stark contrast to an article in The Guardian that made the eye-catching claim that encrypted messaging service WhatsApp is insecure, without making clear that this only applies in an obscure and extremely unlikely set of circumstances.
Zeynep Tufekci, a researcher studying the effects of technology on society, reported that the article was exploited to legitimise misleading advice given by the Turkish government that WhatsApp is unsafe, resulting in human rights activists using SMS instead – which is far easier for the government to censor and monitor.
The Turkish government’s “security advice” to move from WhatsApp to less secure SMS was clearly aimed more at assisting its surveillance efforts than helping the activists to whom the advice was directed. Another case where the advice is more for the benefit of the organisation giving it is that of banks, where the terms and conditions small print gives incomprehensible security advice that isn’t true security advice, instead merely a legal technique to allow the banks wiggle room to refuse to refund victims of fraud.
The discussion board site 4chan has been a part of the Internet’s dark underbelly since its creation, in 2003, by ‘moot’ (Christopher Poole). But recent events have brought it under the spotlight, making it a central figure in the outlandish 2016 US election campaign, with its links to the “alt-right” movement and its rhetoric of hate and racism. However, although 4chan is increasingly “covered” by the mainstream media, we know little about how it actually operates and how instrumental it is in spreading hate on other social platforms. A new study, with colleagues at UCL, Telefonica, and University of Rome now sheds light on 4chan and in particular, on /pol/, the “politically incorrect” board.
What is 4chan anyway?
4chan is an imageboard site, built around a typical bulletin-board model. An “original poster” creates a new thread by making a post, with one single image attached, to a board with a particular focus of interest. Other users can reply, with or without images. Some of 4chan’s most important aspects are anonymity (there is no identity associated with posts) and ephemerality (inactive threads are routinely deleted).
4chan currently features 69 boards, split into 7 high level categories, e.g. Japanese Culture or Adult. In our study, we focused on the /pol/ board, whose declared intended purpose is “discussion of news, world events, political issues, and other related topics”. Arguably, there are two main characteristics of /pol/ threads. One is its racist connotation, with the not-so-unusual aggressive tone, offensive and derogatory language, and links to the “alt-right” movement—a segment of right-wing ideologies supporting Donald Trump and rejecting mainstream conservatism as well as immigration, multiculturalism, and political correctness. The other characteristic is the fact that it generates a substantial amount of original content and “online” culture, ranging from the “lolcats” memes to “pepe the frog.”
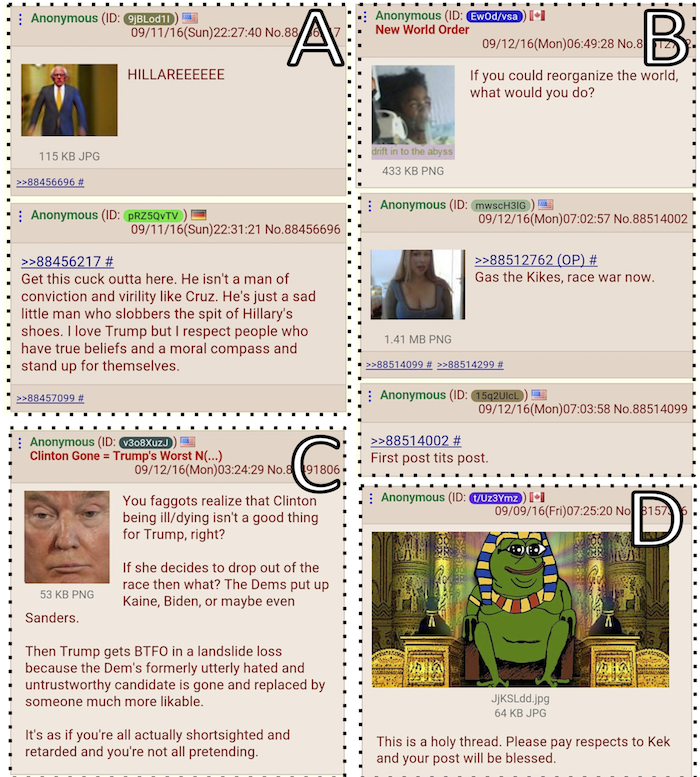
This figure below shows four examples of typical /pol/ threads:
Examples of typical /pol/ threads. Thread (A) illustrates the derogatory use of “cuck” in response to a Bernie Sanders image, (B) a casual call for genocide with an image of a woman’s cleavage and a “humorous” response, (C) /pol/’s fears that a withdrawal of Hillary Clinton would guarantee Donald Trump’s loss, and (D) shows Kek the “god” of memes via which /pol/ believes influences reality.
Raids towards other services
Another aspect of /pol/ is its reputation for coordinating and organizing so-called “raids” on other social media platforms. Raids are somewhat similar to Distributed Denial of Service (DDoS) attacks, except that rather than aiming to interrupt the service at a network level, they attempt to disrupt the community by actively harassing users and/or taking over the conversation.
Contactless card payments are fast and convenient, but convenience comes at a price: they are vulnerable to fraud. Some of these vulnerabilities are unique to contactless payment cards, and others are shared with the Chip and PIN cards – those that must be plugged into a card reader – upon which they’re based. Both are vulnerable to what’s called a relay attack. The risk for contactless cards, however, is far higher because no PIN number is required to complete the transaction. Consequently, the card payments industry has been working on ways to solve this problem.
The relay attack is also known as the “chess grandmaster attack”, by analogy to the ruse in which someone who doesn’t know how to play chess can beat an expert: the player simultaneously challenges two grandmasters to an online game of chess, and uses the moves chosen by the first grandmaster in the game against the second grandmaster, and vice versa. By relaying the opponents’ moves between the games, the player appears to be a formidable opponent to both grandmasters, and will win (or at least force a draw) in one match.
Similarly, in a relay attack the fraudster’s fake card doesn’t know how to respond properly to the payment terminal because, unlike a genuine card, it doesn’t contain the cryptographic key known only to the card and the bank that verifies the card is genuine. But like the fake chess grandmaster, the fraudster can relay the communication of the genuine card in place of the fake card.
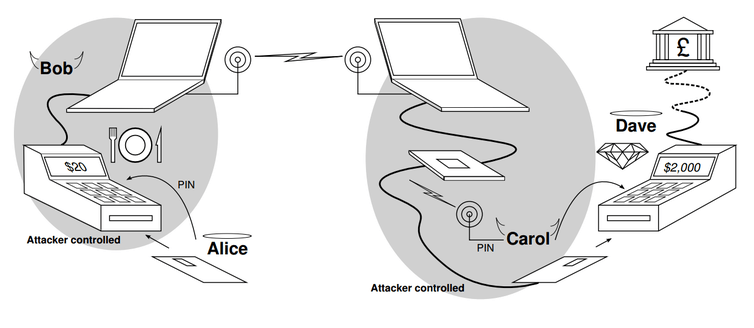
For example, the victim’s card (Alice, in the diagram below) would be in a fake or hacked card payment terminal (Bob) and the criminal would use the fake card (Carol) to attempt a purchase in a genuine terminal (Dave). The bank would challenge the fake card to prove its identity, this challenge is then relayed to the genuine card in the hacked terminal, and the genuine card’s response is relayed back on behalf of the fake card to the bank for verification. The end result is that the terminal used for the real purchase sees the fake card as genuine, and the victim later finds an unexpected and expensive purchase on their statement.
The relay attack, where the cards and terminals can be at any distance from each other
In our scenario, the victim put their card in a fake terminal thinking they were buying a coffee when in fact their card details were relayed by a radio link to another shop, where the criminal used a fake card to buy something far more expensive. The fake terminal showed the victim only the price of a cup of coffee, but when the bank statement arrives later the victim has an unpleasant surprise.
At the time, the banking industry agreed that the vulnerability was real, but argued that as it was difficult to carry out in practice it was not a serious risk. It’s true that, to avoid suspicion, the fraudulent purchase must take place within a few tens of seconds of the victim putting their card into the fake terminal. But this restriction only applies to the Chip and PIN contact cards available at the time. The same vulnerability applies to today’s contactless cards, only now the fraudster need only be physically near the victim at the time – contactless cards can communicate at a distance, even while the card is in the victim’s pocket or bag.
As social networks are increasingly relied upon to engage with people worldwide, it is crucial to understand and counter fraudulent activities. One of these is “like farming” – the process of artificially inflating the number of Facebook page likes. To counter them, researchers worldwide have designed detection algorithms to distinguish between genuine likes and artificial ones generated by farm-controlled accounts. However, it turns out that more sophisticated farms can often evade detection tools, including those deployed by Facebook.
What is Like Farming?
Facebook pages allow their owners to publicize products and events and in general to get in touch with customers and fans. They can also promote them via targeted ads – in fact, more than 40 million small businesses reportedly have active pages, and almost 2 million of them use Facebook’s advertising platform.
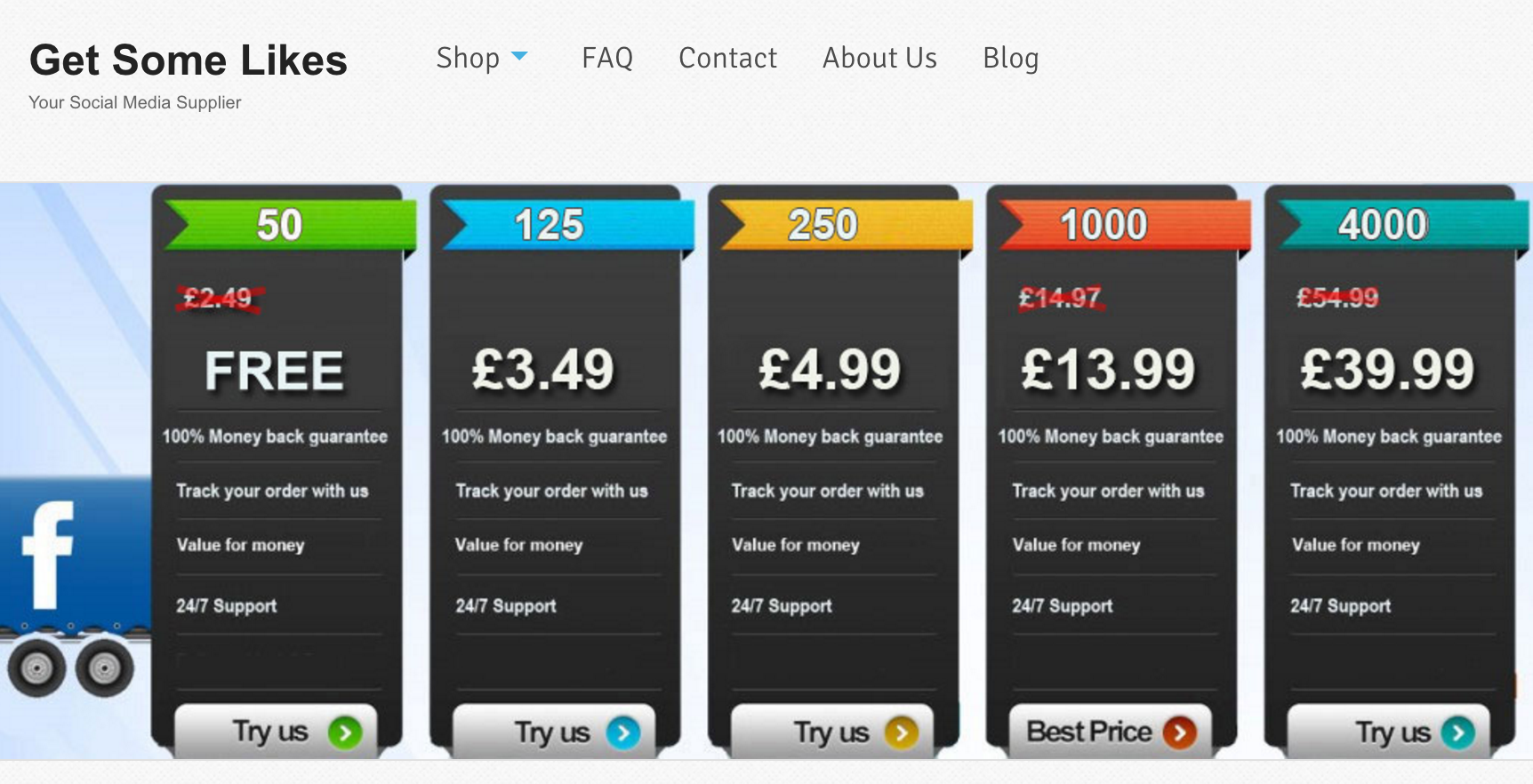
At the same time, as the number of likes attracted by a Facebook page is considered a measure of its popularity, an ecosystem of so-called “like farms” has emerged that inflate the number of page likes. Farms typically do so either to later sell these pages to scammers at an increased resale/marketing value or as a paid service to page owners. Costs for like farms’ services are quite volatile, but they typically range between $10 and $100 per 100 likes, also depending on whether one wants to target specific regions — e.g., likes from US users are usually more expensive.
Screenshot from http://www.getmesomelikes.co.uk/
How do farms operate?
There are a number of possible way farms can operate, and ultimately this dramatically influences not only their cost but also how hard it is to detect them. One obvious way is to instruct fake accounts, however, opening a fake account is somewhat cumbersome, since Facebook now requires users to solve a CAPTCHA and/or enter a code received via SMS. Another strategy is to rely on compromised accounts, i.e., by controlling real accounts whose credentials have been illegally obtained from password leaks or through malware. For instance, fraudsters could obtain Facebook passwords through a malicious browser extension on the victim’s computer, by hijacking a Facebook app, via social engineering attacks, or finding credentials leaked from other websites (and dumped on underground forums) that are also valid on Facebook.
Just how secure is Tor, one of the most widely used internet privacy tools? Court documents released from the Silk Road 2.0 trial suggest that a “university-based research institute” provided information that broke Tor’s privacy protections, helping identify the operator of the illicit online marketplace.
Silk Road and its successor Silk Road 2.0 were run as a Tor hidden service, an anonymised website accessible only over the Tor network which protects the identity of those running the site and those using it. The same technology is used to protect the privacy of visitors to other websites including journalists reporting on mafia activity, search engines and social networks, so the security of Tor is of critical importance to many.
How Tor’s privacy shield works
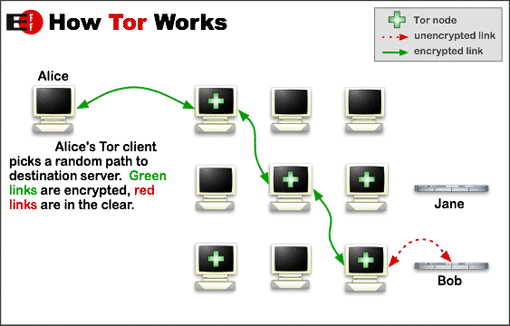
Almost 97% of Tor traffic is from those using Tor to anonymise their use of standard websites outside the network. To do so a path is created through the Tor network via three computers (nodes) selected at random: a first node entering the network, a middle node (or nodes), and a final node from which the communication exits the Tor network and passes to the destination website. The first node knows the user’s address, the last node knows the site being accessed, but no node knows both.
The remaining 3% of Tor traffic is to hidden services. These websites use “.onion” addresses stored in a hidden service directory. The user first requests information on how to contact the hidden service website, then both the user and the website make the three-hop path through the Tor network to a rendezvous point which joins the two connections and allows both parties to communicate.
In both cases, if a malicious operator simultaneously controls both the first and last nodes to the Tor network then it is possible to link the incoming and outgoing traffic and potentially identify the user. To prevent this, the Tor network is designed from the outset to have sufficient diversity in terms of who runs nodes and where they are located – and the way that nodes are selected will avoid choosing closely related nodes, so as to reduce the likelihood of a user’s privacy being compromised.
This type of design is known as distributed trust: compromising any single computer should not be enough to break the security the system offers (although compromising a large proportion of the network is still a problem). Distributed trust systems protect not only the users, but also the operators; because the operators cannot break the users’ anonymity – they do not have the “keys” themselves – they are less likely to be targeted by attackers.
Unpeeling the onion skin
With about 2m daily users Tor is by far the most widely used privacy system and is considered one of the most secure, so research that demonstrates the existence of a vulnerability is important. Most research examines how to increase the likelihood of an attacker controlling both the first and last node in a connection, or how to link incoming traffic to outgoing.
When the 2014 programme for the annual BlackHat conference was announced, it included a talk by a team of researchers from CERT, a Carnegie Mellon University research institute, claiming to have found a means to compromise Tor. But the talk was cancelled and, unusually, the researchers did not give advance notice of the vulnerability to the Tor Project in order for them to examine and fix it where necessary.
This decision was particularly strange given that CERT is worldwide coordinator for ensuring software vendors are notified of vulnerabilities in their products so they can fix them before criminals can exploit them. However, the CERT researchers gave enough hints that Tor developers were able to investigate what had happened. When they examined the network they found someone was indeed attacking Tor users using a technique that matched CERT’s description.
The multiple node attack
The attack turned on a means to tamper with a user’s traffic as they looked up the .onion address in the hidden service directory, or in the hidden service’s traffic as it uploaded the information to the directory.
Norwegian writer Mette Newth once wrote that: “censorship has followed the free expressions of men and women like a shadow throughout history.” Indeed, as we develop innovative and more effective tools to gather and create information, new means to control, erase and censor that information evolve alongside it. But how do we study Internet censorship?
Organisations such as Reporters Without Borders, Freedom House, or the Open Net Initiative periodically report on the extent of censorship worldwide. But as countries that are fond of censorship are not particularly keen to share details, we must resort to probing filtered networks, i.e., generating requests from within them to see what gets blocked and what gets through. We cannot hope to record all the possible censorship-triggering events, so our understanding of what is or isn’t acceptable to the censor will only ever be partial. And of course it’s risky, or even outright illegal, to probe the censor’s limits within countries with strict censorship and surveillance programs.
This is why the leak of 600GB of logs from hardware appliances used to filter internet traffic in and out of Syria was a unique opportunity to examine the workings of a real-world internet censorship apparatus.
Leaked by the hacktivist group Telecomix, the logs cover a period of nine days in 2011, drawn from seven Blue Coat SG-9000 internet proxies. The sale of equipment like this to countries such as Syria is banned by the US and EU. California-based manufacturer Blue Coat Systems denied making the sales but confirmed the authenticity of the logs – and Dubai-based firm Computerlinks FZCO later settled on a US$2.8m fine for unlawful export. In 2013, researchers at the University of Toronto’s Citizen Lab demonstrated how authoritarian regimes in Saudi Arabia, UAE, Qatar, Yemen, Egypt and Kuwait all rely on US-made equipment like those from Blue Coat or McAfee’s SmartFilter software to perform filtering.
The Chip and PIN card payment system has been mandatory in the UK since 2006, but only now is it being slowly introduced in the US. In western Europe more than 96% of card transactions in the last quarter of 2014 used chipped credit or debit cards, compared to just 0.03% in the US.
Yet at the same time, in the UK and elsewhere a new generation of Chip and PIN cards have arrived that allow contactless payments – transactions that don’t require a PIN code. Why would card issuers offer a means to circumvent the security Chip and PIN offers?
Chip and Problems
Chip and PIN is supposed to reduce two main types of fraud. Counterfeit fraud, where a fake card is manufactured based on stolen card data, cost the UK £47.8m in 2014 according to figures just released by Financial Fraud Action. The cryptographic key embedded in chip cards tackles counterfeit fraud by allowing the card to prove its identity. Extracting this key should be very difficult, while copying the details embedded in a card’s magnetic stripe from one card to another is simple.
The second type of fraud is where a genuine card is used, but by the wrong person. Chip and PIN makes this more difficult by requiring users to enter a PIN code, one (hopefully) not known to the criminal who took the card. Financial Fraud Action separates this into those cards stolen before reaching their owner (at a cost of £10.1m in 2014) and after (£59.7m).
Unfortunately Chip and PIN doesn’t work as well as was hoped. My research has shown how it’s possible to trick cards into accepting the wrong PIN and produce cloned cards that terminals won’t detect as being fake. Nevertheless, the widespread introduction of Chip and PIN has succeeded in forcing criminals to change tactics – £331.5m of UK card fraud (69% of the total) in 2014 is now through telephone, internet and mail order purchases (known as “cardholder not present” fraud) that don’t involve the chip at all. That’s why there’s some surprise over the introduction of less secure contactless cards.
Using Bluetooth wireless networking to send information to nearby smartphones, beacon technology could transform how retailers engage with their customers. But customers will notice how their information is used to personalise these unsolicited adverts, and companies that fail to respect their privacy may get burned.
UK retailer House of Fraser is to introduce beacon-equipped mannequins to its Aberdeen store, which will deliver details about the clothes and accessories the mannequin is wearing to the smartphones of customers within 50 metres. In London’s Regent Street, around 100 stores have installed Apple’s iBeacons, able to send adverts to smartphones to entice passers-by to come inside.
A sort of precursor to the “internet of things”, beacon technology has great potential to enhance consumer experience: providing access to relevant information more quickly, or offering rewards and discounts for loyal shoppers. Some retailers may rearrange their store based on analysing data from customers’ shopping habits. It has uses outside of marketing too, such as providing contactless payments, tourist information at museums, or gate information at airports.
Genomics is increasingly hailed by many as the turning point in modern medicine. Advances in technology now mean we’re able to make out the full DNA sequence of an organism and decipher its entire hereditary information, bringing us closer to discovering the causes of particular diseases and disorders and drugs that can be targeted to the individual.
Buzzwords like “whole genome sequencing” and “personalised medicine” are everywhere – but how are they enabling a powerful medical and societal revolution?
It all started in the 1990’s with the Human Genome Project – a very ambitious venture involving 20 international partners and an investment of US$3 billion. In 2003, 13 years after it began, the project yielded the first complete human genome. Today, the cost of sequencing whole genomes is plummeting fast and it is now possible to do the job for less than US$1,000, meaning a whole host of applications both in research and in treatments.
Variants and mutations
Genetic mutations are often linked to disorders, predisposition to diseases and response to treatment. For instance, inherited genetic variants can cause blood disorders such as thalassaemia or others such as cystic fibrosis or sickle cell anaemia.
Genome sequencing is being used today in diagnostic and clinical settings to find rare variants in a patient’s genome, or to sequence cancers’ genomes (to point out genomic differences between solid tumours and develop a more effective therapeutic strategy). It is also possible to test for known simple mutations via a process called genotyping, which can find genetic differences through a set of biomarkers. In the case of thalassemia, for example, there are mutations in the HBB gene on chromosome 11.
A number of drugs, including blood-thinners like warfarin, have already been commercialised with genetic markers (such as a known location on a chromosome) linked to effectiveness and correct dosage.




{kind=link}