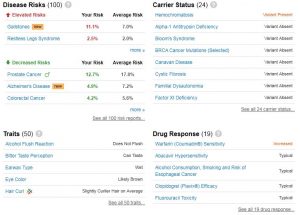
In 2014, Harvard professor and geneticist George Church said: “‘Preserving your genetic material indefinitely’ is an interesting claim. The record for storage of non-living DNA is now 700,000 years (as DNA bits, not electronic bits). So, ironically, the best way to preserve your electronic bitcoins/blockchains might be to convert them into DNA”. In early February 2018, Nebula Genomics, a blockchain-enabled genomic data sharing and analysis platform, co-founded by George Church, was launched. And they are not alone on the market. The common factor between all of them is that they want to give the power back to the user. By leveraging the fact that most companies that currently offer direct-to-consumer genetic testing sell data collected from their customers to pharmaceutical and biotech companies for research purposes, they want to be the next Uber or Airbnb, with some even claiming to create the Alibaba for life data using the next-generation artificial intelligence and blockchain technologies.
In 2014, Harvard professor and geneticist George Church said: “‘Preserving your genetic material indefinitely’ is an interesting claim. The record for storage of non-living DNA is now 700,000 years (as DNA bits, not electronic bits). So, ironically, the best way to preserve your electronic bitcoins/blockchains might be to convert them into DNA”. In early February 2018, Nebula Genomics, a blockchain-enabled genomic data sharing and analysis platform, co-founded by George Church, was launched. And they are not alone on the market. The common factor between all of them is that they want to give the power back to the user. By leveraging the fact that most companies that currently offer direct-to-consumer genetic testing sell data collected from their customers to pharmaceutical and biotech companies for research purposes, they want to be the next Uber or Airbnb, with some even claiming to create the Alibaba for life data using the next-generation artificial intelligence and blockchain technologies.
Nebula Genomics
![]()
Its launch is motivated by the need of increasing genomic data sharing for research purposes, as well as reducing the costs of sequencing on the client side. The Nebula model aims to eliminate personal genomics companies as the middle-man between the customer and the pharmaceutical companies. This way, data owners can acquire their personal genomic data from Nebula sequencing facilities or other sources, join the Nebula network and connect directly with the buyers.
Their main claims from their whitepaper can be summarized as follows:
- Lower the sequencing costs for customers by joining the network to profiting from directly by connecting with data buyers if they had their genomes sequenced already, or by participating in paid surveys, which can incentivize data buyers to subsidize their sequencing costs
- Enhanced data protection: shared data is encrypted and securely analyzed using Intel Software Guard Extensions (SGX) and partially homomorphic encryption (such as the Paillier scheme)
- Efficient data acquisition, enabling data buyers to efficiently acquire large genomic datasets
- Being big data ready, by allowing data owners to privately store their data, and introducing space efficient data encoding formats that enable rapid transfers of genomic data summaries over the network
Zenome
 This project aims to ensure that genomic data from as many people as possible will be openly available to stimulate new research and development in the genomics industry. The founders of the project believe that if we do not provide open access to genomic data and information exchange, we are at risk of ending up with thousands of isolated, privately stored collections of genomic data (from pharmaceutical companies, genomic corporations, and scientific centers), but each of these separate databases will not contain sufficient data to enable breakthrough discoveries. Their claims are not as ambitious as Nebula, focusing more on the customer profiting from selling their own DNA data rather than other sequencing companies. Their whitepaper even highlights that no valid solutions currently exist for the public use of genomic information while maintain individual privacy and that encryption is used when necessary. When buying ZNA tokens (the cryptocurrency associated with Zenome), one has to follow a Know-Your-Customer procedure and upload their ID/Passport.
This project aims to ensure that genomic data from as many people as possible will be openly available to stimulate new research and development in the genomics industry. The founders of the project believe that if we do not provide open access to genomic data and information exchange, we are at risk of ending up with thousands of isolated, privately stored collections of genomic data (from pharmaceutical companies, genomic corporations, and scientific centers), but each of these separate databases will not contain sufficient data to enable breakthrough discoveries. Their claims are not as ambitious as Nebula, focusing more on the customer profiting from selling their own DNA data rather than other sequencing companies. Their whitepaper even highlights that no valid solutions currently exist for the public use of genomic information while maintain individual privacy and that encryption is used when necessary. When buying ZNA tokens (the cryptocurrency associated with Zenome), one has to follow a Know-Your-Customer procedure and upload their ID/Passport.
Gene Blockchain
![]() The Gene blockchain business model states it will use blockchain smart contracts to:
The Gene blockchain business model states it will use blockchain smart contracts to:
- Create an immutable ledger for all industry related data via GeneChain
- Offer payment for industry related services and supplies through GeneBTC
- Establish advanced labs for human genome data analysis via GeneLab
- Organize and unite global platform for health, entertainment, social network and etc. through GeneNetwork