The introduction of ZCash, and subsequent articles explaining the technology, brought (slightly more) mainstream attention to a situation that people interested in blockchain technology have been aware of for quite a while: Bitcoin doesn’t provide users with a lot of anonymity.
Bitcoin instead provides a property referred to as pseudonymity (derived from pseudonym, meaning ‘false name’). Spending and receiving bitcoin can be done without transacting parties ever learning each other’s off-chain (real world) identities. Users have a private key with which to spend their funds, a public key so that they can receive funds, and an address where the funds are stored, on the blockchain. However, even if addresses are frequently changed, very revealing analysis can be performed on the information stored in the blockchain, as all transactions are stored in the clear.
For example, imagine if you worked at a small company and you were all paid in bitcoin – based on your other purchases, your colleagues could have a very easy time linking your on-chain addresses to you. This is more revealing than using a bank account, and we want cryptocurrencies to offer better properties than bank accounts in every way. Higher speed, lower cost and greater privacy of transfers are all essential.
ZCash is a whole different ball game. Instead of sending transactions in the clear, with the transaction value and sender and recipient address stored on the blockchain for all to see, ZCash transactions instead produce a zero-knowledge proof that the sender owns an amount of ZEC greater than or equal to the amount that they are trying to spend.
Put more simply, you can submit a proof that you have formed a transaction properly, rather than submitting the actual transaction to be stored forever on the blockchain. These proofs take around 40 seconds to generate, and the current supply of ZCash is a very limited 7977 ZEC. So I’m going to take you through some privacy enhancing methods that work on top of Ethereum, a cryptocurrency with approximately 15 second blocktimes and a current market cap of nearly $1 billion. If we do everything right, our anonymous transactions might even be mined before the ZCash proof has even finished generating.
Blockchains
If a lot of the words above meant nothing to you, here’s a blockchain/Bitcoin/Ethereum/smart contract primer. If you already have your blockchain basics down, feel free to skip to part 2.
Bitcoin
Satoshi Nakamoto introduced the world to the proof-of-work blockchain, through the release of the bitcoin whitepaper in 2008, allowing users and interested parties to consider for the first time a trustless system, with which it is possible to securely transfer money to untrusted and unknown recipients. Since its launch, the success of bitcoin has motivated the creation of many other cryptocurrencies, both those built upon Bitcoin’s underlying structure, and those built entirely independently.
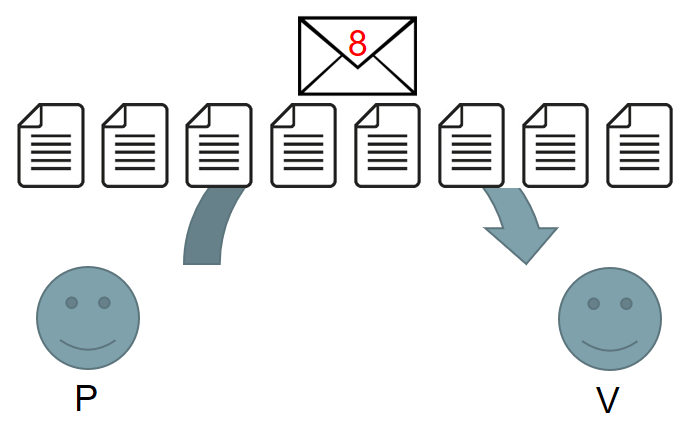
Cryptocurrencies are most simply described as ‘blockchains’ with a corresponding token or coin, with which you can create transactions that are then verified and stored in a block on the underlying blockchain. Put even more simply, they look a little like this:
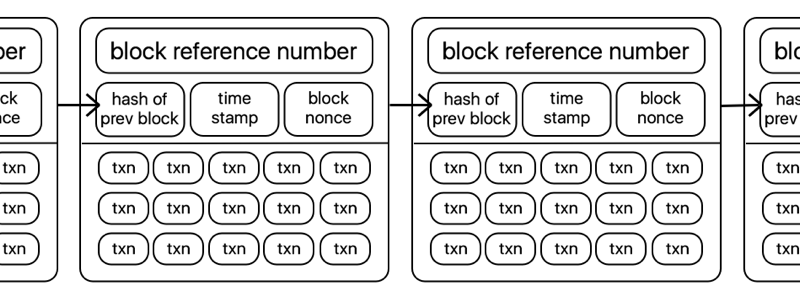
Transactions in bitcoin are generally simple transfers of tokens from one account to another, and are stored in a block in the clear, with transaction value, sender, and recipient all available for any curious individual to view, analyse, or otherwise trace.
The blockchain has a consensus algorithm. This is essential for construction of one agreed-upon set of transactions, rather than multiple never-converging views of who currently owns which bitcoins.
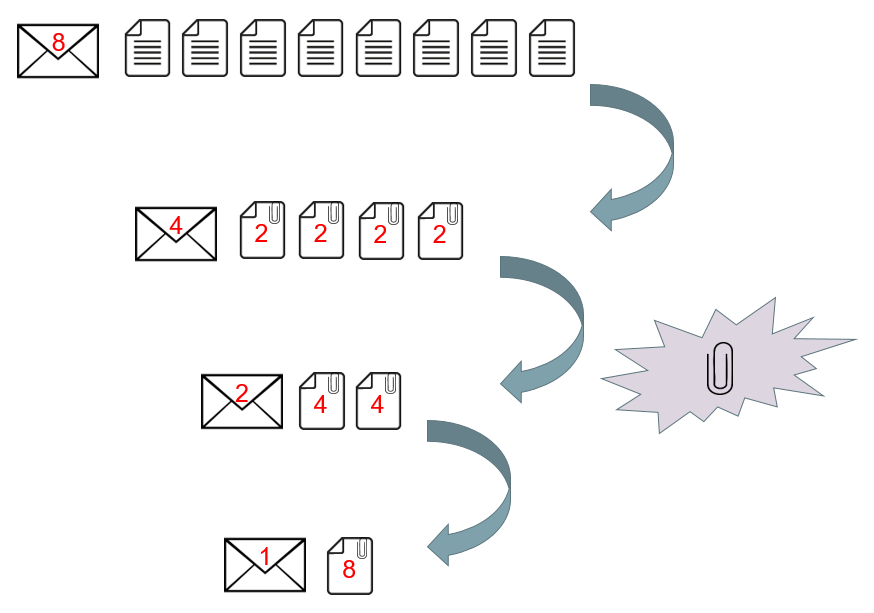
The most common consensus algorithms in play at the moment are ‘proof of work’ algorithms, which require a computationally hard ‘puzzle’ to be solved by miners (a collection of competing participants) in order to make the cost of subverting or reversing transactions prohibitively expensive. Transactions are verified and mined as follows:
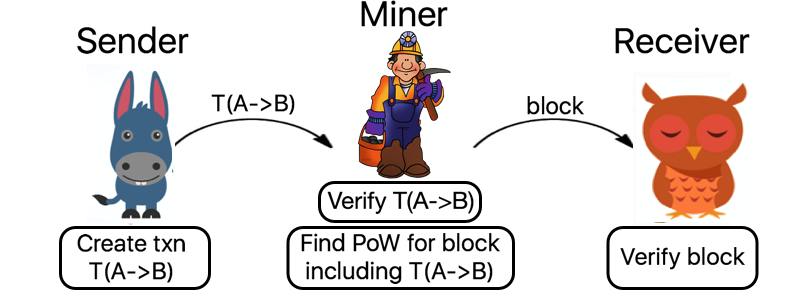
To really understand how the privacy enhancing protocol conceived and implemented during my Master’s thesis works, we need to go a little deeper into the inner workings of a blockchain platform called Ethereum.
Ethereum: Programmable Money
In response to the limitations of Bitcoin’s restricted scripting language (you can pretty much only transfer money from A to B with Bitcoin, for security reasons), the Ethereum platform was created, offering an (almost) Turing-complete distributed virtual machine atop the Ethereum blockchain, along with a currency called Ether. The increased scripting ability of the system enables developers to create ‘smart contracts’ on the blockchain, programs with rich functionality and the ability to operate on the blockchain state. The blockchain state records current ownership of money and of the local, persistent storage offered by Ethereum. Smart contracts are limited only by the amount of gas they consume. Gas is a sub-currency of the Ethereum system, existing to impose a limit on the amount of computational time an individual contract can use.
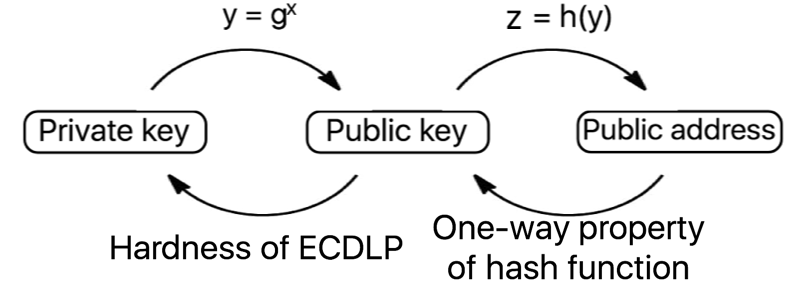
Ethereum accounts take one of two forms – either they are ‘externally owned’ accounts, controlled with a private key (like all accounts in the bitcoin system), or ‘contracts’, controlled by the code that resides in the specific address in question. Contracts have immutable code stored at the contract address, and additional storage which can be read from and written to by the contract. An Ethereum transaction contains the destination address, optional data, the gas limit, the sequence number and signature authorising the transaction. If the destination address corresponds to a contract, the contract code is then executed, subject to the gas limit as specified in the transaction, which is used to allow a certain number of computational steps before halting.
The ability to form smart contracts suggests some quite specific methods of addressing the lack of privacy and corresponding potential lack of fungibility of coins in the Ethereum system. Although cryptocurrencies provide some privacy with the absence of identity related checks required to buy, mine, or spend coins, the full transaction history is public, enabling any motivated individual to track and link users’ purchases. This concept heavily decreases the fungibility of cryptocurrencies, allowing very revealing taint analysis of coins to be performed, and leading to suggestions of blacklisting coins which were once flagged as stolen.
With smart contracts, we can do magical things, starting in part 2