This is the story of the most popular execution environment, its shortcomings, and how open source and hacking saved the day.
According to recent revelations, the MINIX operating system is embedded in the Management Engine of all Intel CPUs released after 2015. A side-effect of this is that MINIX became known as the most widespread operating system in the world almost overnight. However, in the last decade another tiny OS has silently pushed itself into even more devices around the world while remaining unknown to most: JavaCard.

With more than six billion JavaCards sold last year, and approximately 20 billion estimated to have been purchased in total, JavaCard is the winner no one knows about. The execution environment was designed in 1996 for devices with limited memory and processing capabilities and was the first smartcard platform to give developers the ability to execute the same applet on cards produced by different manufacturers. This was a breakthrough for the industry that established JavaCard as the default platform for applications in need of a secure, tamper-proof element.
*While JavaCard is technically not an OS in the standard sense (smart cards do have their own proprietary OSes), in practice it provides very similar functionality with modern embedded OSes. For instance, unless granted by the vendor, app developers are strictly limited within the JavaCard runtime environment; this distinguishes JavaCard from e.g, the classic Java VM where developers can also execute native applications in addition to those executed in the JVM.
A malfunctioning operating system
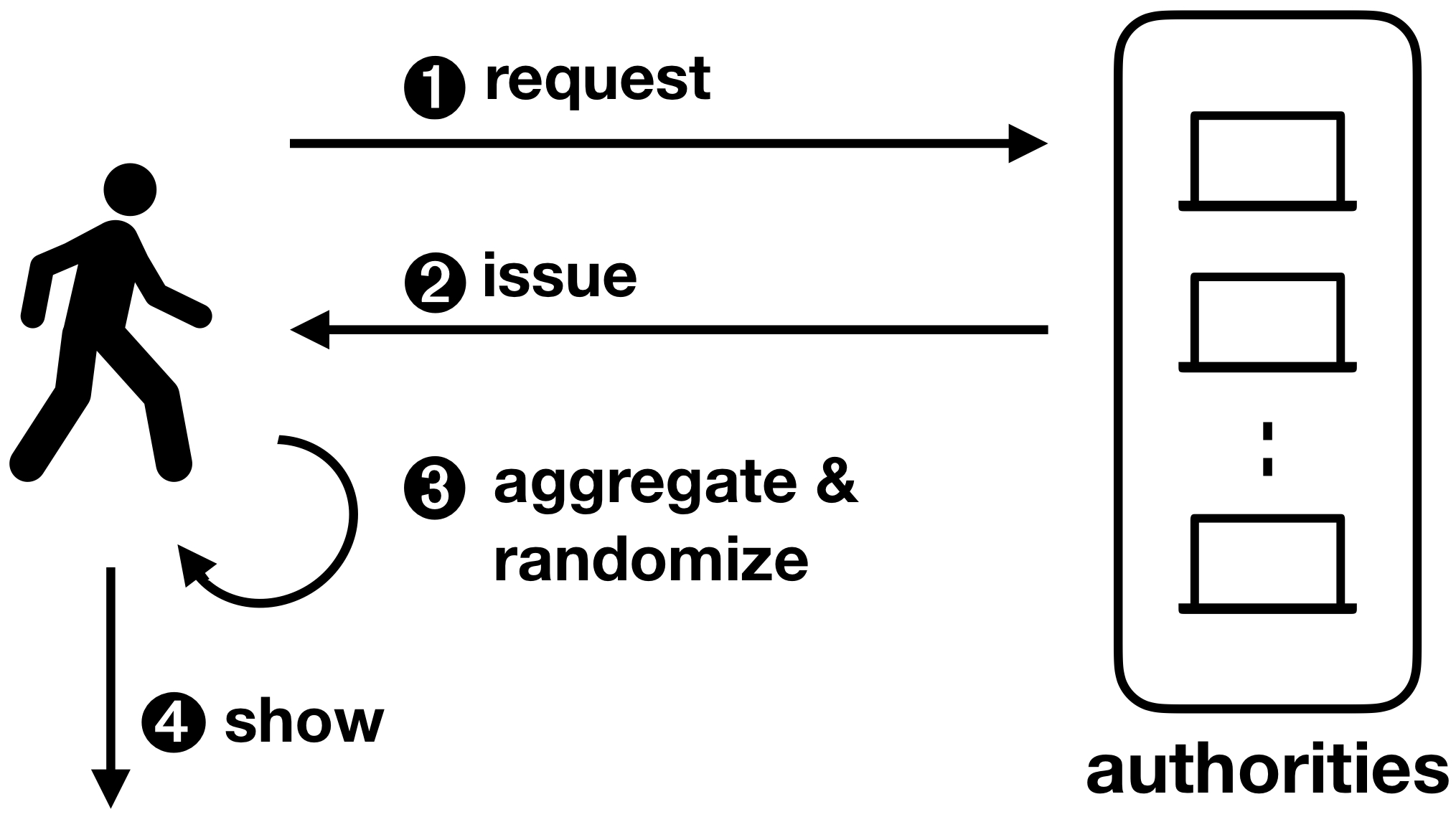
An operating system is much more than the sum of its source code: it’s also the ecosystem built around it, including the specifications, support, and most importantly the application developers and the user community.
For JavaCard, the specification part is handled formally by Oracle and Java Card Forum who make periodical releases of the platform’s virtual machine (JCVM) specification, runtime library (JCRL) and application programming interface (JC API). All these contribute towards homogeneity between cards from different manufacturers; aiming to ensure applet interoperability and a minimum level of support for basic cryptographic algorithms – at least in theory. In practice, our research has shown that no product in the market implements JC API completely, and different cards support different sets of features. This severely hinders the interoperability of applications and constrains developers within the limited subset of JavaCard features supported by most manufacturers. Developers who choose to use all the features provided by a specific card will, with high likelihood, abolish the interoperability of their applets. Furthermore, some of those specifications are also inadvertently limiting the scope of the platform. For instance, the API specification that lists all the calls to be potentially available to smart card applications ended up acting as an evolutionary bottleneck. This is due to:
- Approximately three-year-long API revision cycles that severely delay support for newer cryptographic algorithms (the last API revision was released in 2015).
- More complex cryptographic operations (especially asymmetric cryptography) requiring design and production of dedicated hardware accelerators to actually support newly added cryptographic algorithms.
- The business model is geared towards the large corporations. Hence, newer cards are available only to those buying in large quantities while smaller development houses and researchers are forced to work with five years old, or even older, cards.
Continue reading JavaCard: The execution environment you didn’t know you were using

{kind=link}
{kind=link}