
This post introduces the problem of backdoors embedded in deep reinforcement learning agents and discusses our proposed defence. For more technical details please see our paper and the project’s repo.
Deep Reinforcement Learning (DRL) has the potential to be a game-changer in process automation. From automating the decision-making in self-driving cars, to aiding medical diagnosis, to even advancing nuclear fusion plasma control efficiency. While the real-world applications for DRL are innumerable, the development process of DRL models is resource-intensive by nature and often exceeds the resource allocation limits of smaller entities, leading to a dependency on large organisations. This reliance introduces significant risks, including potential policy defects that can result in unsafe agent behaviour during certain phases of its operation.
Instances of unsafe agent behaviour can stem from backdoor attacks aimed at DRL agent policies. Backdoor attacks on AI agents involve intentional policy defects, designed to trigger unexpected agent behaviour deviations given specific environmental cues. An example of a standard backdoor can be seen in the top left corner Figure 1b, which appears in the form of a 3×3 grey pixel that unexpectedly appears every given interval, leading to deviations in DRL agent behaviour.
 |
 |
Figure 1a and 1b: GIFs of Atari Breakout episodes showing a clean DRL policy without a backdoor trigger (encapsulated in a red outline) and a backdoored policy of a DRL agent with a grey 3×3 pixel trigger in Figure 1a and 1b respectively.
The state-of-the-art solution against backdoor attacks currently proposes defence against standard backdoors. However, the solution requires extensive compute time to successfully sanitise the DRL agent from the poisoned policies ingrained within. Figure 1b below illustrates how the defence successfully filters the backdoor policy by creating a “safe subspace” to remove anomalous states in the environment and allow benign agent operations.
 |
 |
Figure 2a and 2b: GIFs of an Atari Breakout episode played by a poisoned DRL agent with a standard backdoor trigger added in the top left corner (encapsulated inside a red outline). 2a is an episode with no defence and 1b is an episode with the current state-of-the-art defence and sanitisation algorithm.
To assess the effectiveness of the current state-of-the-art solution against more elusive backdoors attacks, we investigate in-distribution backdoors, which are attacks that occur through changes in the agent’s environment that are not anomalous to the overall data encountered by the agent. We design a trigger that appears as a missing tile in the environment and apply the state-of-the-art algorithm against this backdoor. As a result, we observe that it is unable to filter out this backdoor due to its stealthy appearance (shown in Figure 2).

Figure 2: Breakout Atari game played by a DRL agent poisoned by an in-distribution backdoor that appears as a missing tile in the middle of the tile space (encapsulated in a red outline).
The absence of viable solutions in this domain constitutes a major obstacle in the deployment of DRL algorithms in real-world applications. Depending on the application, the susceptibility to in-distribution backdoor attacks could enable adversaries to orchestrate catastrophic outcomes, ranging from vehicular mishaps in autonomous driving systems, to misdiagnoses in medical settings, and potentially life-threatening risks within nuclear fusion operations. This poses a significant challenge for DRL in real-world operations, with the possibility of halting its integration across various real-world domains where it holds tremendous promise.
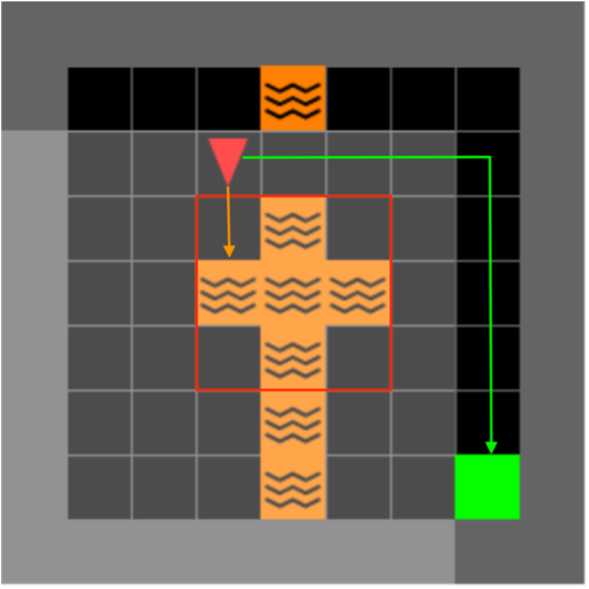
To detect backdoor attacks that remain concealed, we utilise an adapted version of the MiniGrid Lava Crossings environment, which offers increased variability due to its randomised configurations of lava “rivers” in each episode. Our in-distribution backdoor resembles a ‘+’ sign formed by lava rivers, directing the agent to enter the lava upon sighting it.
 |
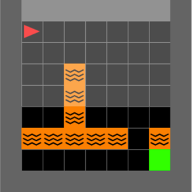 |
Figure 3a and 3b : Modified Lava Crossings environment comprising of the original 6 box lava river with a gap along with another 3 box river. The “+” sign is characterised as an in-distribution backdoor due to its existence being natural within the randomised arrangement of lava ‘rivers’ for every episode.
Using existing research in anomaly detection, we hypothesise that the neural patterns of DRL agents can be used in distinguishing between benign and backdoor-altered decision-making processes. To explore this, we train a Proximal Policy Optimisation (PPO) agent using a neural network with a 256-neuron actor-critic framework. The simplified design facilitates the observation of neural activations, aiding in the detection of divergences between benign and backdoor-based episodes. In a controlled environment, the agent navigates towards a green square to demonstrate benign behaviour, as shown in Figure 3a, whereas the presence of a backdoor trigger causes it to deviate into the lava, as depicted in Figure 3b.
With our compromised model, we examine the neural activity across 1,000 benign and 1,000 backdoor episodes. This analysis reveals a significant difference in the actor network’s average neural activity between the scenarios, as illustrated in the figure below.
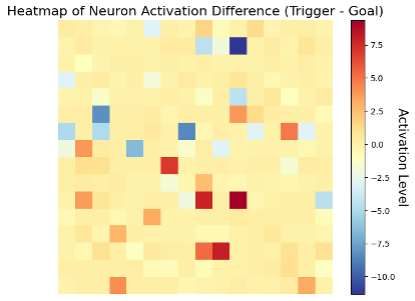
Figure 4: Average neuron activation difference when comparing the average of 256 neuron activations of the actor network during the triggered episodes and goal episodes.
We delve further into the neuron activation level distribution of the most impacted neurons and discovered significantly different distributions in the two scenarios (shown in figures below).
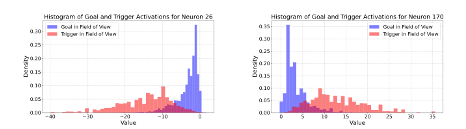
Figure 5a and 5b: Activation distribution difference of specific neurons when the 1) Goal is in the field of view and 2) Trigger is in the field of view.
We delve further into the neuron activation level distribution of the most impacted neurons and discovered significantly different distributions in the two scenarios (shown in figures below).


Figure 6a and 6b: GIFs showing the neuron activation level transition during triggered and non-triggered episodes.
After discovering that distinct neural activity is exhibited in the visuals above when backdoors are present, we parameterise lightweight classifiers based on upper and lower percentile levels of neuron activations. The visual below offers a glimpse into the performance of our detectors, where they successfully identify hidden backdoors through neural activations, achieving F1 scores over 93%. This finding takes us a step closer towards the real-world deployment of DRL as it confirms the significant potential of neural activations in detecting backdoor threats in real-time for DRL within operation. For example, in an application scenario involving Autonomous Cars, the human driver could be immediately given control instead of allowing the algorithm to take malicious actions when the trigger appears in its vision.
Through this work, we advance beyond the existing benchmarks for backdoor detection research in DRL by introducing a robust, real-time method capable of identifying even the most elusive backdoors present in an environment. The insights from our research pave new pathways for applying our findings across various algorithms and contexts regarding backdoor threats. Furthermore, this breakthrough enables the assessment of temporal backdoors through neural activation sequences in compromised agents, a domain that presently lacks effective solutions.
Acknowledgements
Research funded by the Defence Science and Technology Laboratory (Dstl) which is an executive agency of the UK Ministry of Defence providing world class expertise and delivering cutting-edge science and technology for the benefit of the nation and allies. The research supports the Autonomous Resilient Cyber Defence (ARCD) project within the Dstl Cyber Defence Enhancement programme.