Tor hidden services offer several security advantages over normal websites:
- both the client requesting the webpage and the server returning it can be anonymous;
- websites’ domain names (.onion addresses) are linked to their public key so are hard to impersonate; and
- there is mandatory encryption from the client to the server.
However, Tor hidden services as originally implemented did not take full advantage of parallel processing, whether from a single multi-core computer or from load-balancing over multiple computers. Therefore once a single hidden service has hit the limit of vertical scaling (getting faster CPUs) there is not the option of horizontal scaling (adding more CPUs and more computers). There are also bottle-necks in the Tor networks, such as the 3–10 introduction points that help to negotiate the connection between the hidden service and the rendezvous point that actually carries the traffic.
For my MSc Information Security project at UCL, supervised by Steven Murdoch with the assistance of Alec Muffett and other Security Infrastructure engineers at Facebook in London, I explored possible techniques for improving the horizontal scalability of Tor hidden services. More precisely, I was looking at possible load balancing techniques to offer better performance and resiliency against hardware/network failures. The focus of the research was aimed at popular non-anonymous hidden services, where the anonymity of the service provider was not required; an example of this could be Facebook’s .onion address.
One approach I explored was to simply run multiple hidden service instances using the same private key (and hence the same .onion address). Each hidden service periodically uploads its own descriptor, which describes the available introduction points, to six hidden service directories on a distributed hash table. The hidden service instance chosen by the client depends on which hidden service instance most recently uploaded its descriptor. In theory this approach allows an arbitrary number of hidden service instances, where each periodically uploads its own descriptors, overwriting those of others.
This approach can work for popular hidden services because, with the large number of clients, some will be using the descriptor most recently uploaded, while others will have cached older versions and continue to use them. However my experiments showed that the distribution of the clients over the hidden service instances set up in this way is highly non-uniform.
I therefore ran experiments on a private Tor network using the Shadow network simulator running multiple hidden service instances, and measuring the load distribution over time. The experiments were devised such that the instances uploaded their descriptors simultaneously, which resulted in different hidden service directories receiving different descriptors. As a result, clients connecting to a hidden service would be balanced more uniformly over the available instances.
This provided an adequate level of load distribution, and although the distribution was still not split evenly, performance was greatly improved. The figure below shows a comparison between experiments using 1, 2, 3 and 6 hidden service instances, measuring the time it takes to repeatedly download 1MB of data. By increasing the number of hidden service instances the time taken for all downloads to complete falls dramatically.
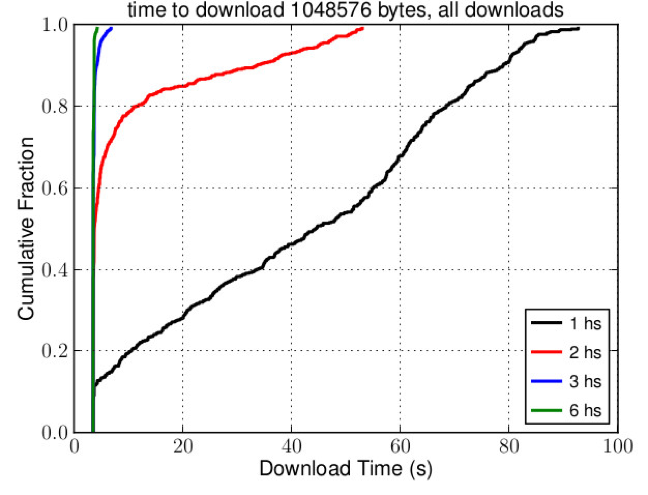
This experiment showed that load balancing was possible by running multiple hidden service instances and arranging that the hidden service directories had descriptors belonging to different instances. In order to replicate this in a live Tor network, I wrote program to sit in the background and re-upload the descriptors of each instance to the hidden service directories such that descriptors are distributed as evenly as possible across the six responsible hidden service directories. The figure below shows how a setup involving 3 hidden service instances A, B, C would upload their descriptors on the distributed hash table.
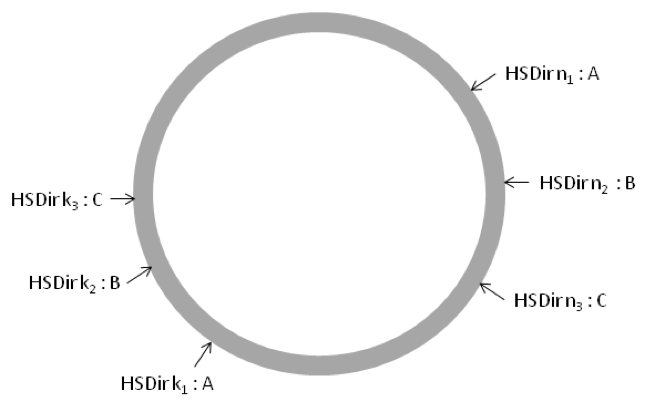
This, in effect, provides randomized load distribution because clients randomly pick from the set of six responsible directories when downloading a hidden service descriptor. This also allows for fail-over capabilities, because if one of the hidden service instances fails, a client simply queries the other hidden service directories one by one until it receives a descriptor for an available instance. Another important consequence is that this approach results in different introduction points for each descriptor, and as a result the load on any given introduction point is reduced. Tests using this method revealed a much more even split across the hidden service instances, when compared to naïvely running multiple hidden service instances.
This new approach allows for up to six hidden service instances to be utilised, however it brings up the issue of how to best schedule the upload of hidden service descriptors. For simplicity during the experiments, the mix of selected descriptors was uploaded immediately after any of the instances republished theirs.
Another approach to hidden service scalability is implemented by OnionBalance, a tool that provides load balancing by producing a master descriptor which contains a mix of introduction points from different hidden service instances. This approach is limited by the maximum number of introduction points available (currently ten). The OnionBalance approach could be combined with my design, so that six different master descriptors could be uploaded to different hidden service directories. This hybrid approach allows a maximum of sixty hidden service instances being simultaneously available.
The solutions described have the potential to work well, but still require improvement and testing. Further details on the approach and the evaluation I performed can be found in my MSc thesis.